
The new interiors mentioned earlier are in the game, now.


![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

Frogatto & Friends is an action-adventure platformer game, starring a certain quixotic frog.
We're an open-source community project, and welcome contributions!
We also have a very flexible editor and engine you can use to make your own creations.
The new interiors mentioned earlier are in the game, now.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
After a bunch of work, we have a useable set of ground tiles for the forest, which means (pending some additional branches for platforms) we can go ahead with making all the forest levels soon. Here’s a preview of what it looks like:


![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Frogatto implements a common feature in modern tile-based games, called “auto-tiling.” For those who aren’t familiar, here’s a quick description.

a typical 8-bit brick tile
The earliest tile-based games, usually 8-bit or pre-8-bit games like super-mario brothers, had very simple tiles. For a given kind of tile, they typically only had a single image. They didn’t have borders, they didn’t have edges; no variations. Just one, single image which would get repeated over and over again. This was about all they could achieve with the limited graphics and memory on ancient systems; with the few colors available onscreen, and with tools to make game graphics in their infancy, it was more of an achievement to ship a game at all, than to try the herculean task of trying to make it look good.
Borders:

some early, bordered tiles from frogatto
The next obvious step was making tiles that had visible borders Rather than drawing just one tile, you would draw a set of tiles that had a visible edge on them. The set of possible arrangements of one tile next to the surrounding 8 is finite, and can be completely drawn; the set of common arrangements is even smaller, and if you choose to draw only those, it actually becomes trivial (perhaps only some dozen unique tiles to provide all the common arrangement). After that, perhaps you would make a few unique variations of common tiles; alternate versions of a tile to be randomly used to make something more organic.
The problem:
To anyone who has worked on creating levels for a videogame, this creates a great deal more work, not merely in making the graphics, but in editing the levels. Editing the levels is much like using a simple bitmap graphics program (like ms-paint), you select a type of tile to place, and you click to ‘draw’ them with a pencil tool. The problem is each different border tile gets treated as a separate thing you have to choose to place. Where before you had only one ‘brick’ tile, you now have over a dozen of them, each representing a possible border arrangement. You have to constantly flick back and forth between your palette of tiles and the level you’re placing them on, whereas before you could just select one tile, and freely paint a whole section filled with it. It’s a classical “efficiency expert’s” nightmare.
The Solution:

What autotiling automates.
The first thought that popped into anyone’s mind, frustrated by this, was “geez, can’t we program a computer to do this for us?” Given the simple, mathematical nature of the problem, the answer was “yes”. Autotiling is exactly that. It is a system where, as you draw tiles onto a level, the game automatically checks the surrounding tiles and places the border tile appropriate to that spot. All you have to do is select a general type of tile, such as brick, or grey stone, and draw in the arrangement you would like; the game automagically picks the correct arrangement of borders appropriate for what you placed.

An set of the components needed to freely arrange borders.
In an upcoming post, I’ll describe how frogatto’s auto-tiling system works from the programmer’s point of view.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Neorice made some new interior graphics; these will replace the current ones in-game, once I deal with the joys of figuring out the tiling logic.

We also have a new set of scaffolding tiles in the game already:

This is an example of just how flexible these new scaffold pieces are:

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Over the past couple weeks, I’ve been working on getting Frogatto to run on the iPhone. I started by re-doing all the drawing code to be compatible with OpenGL ES. After that I set up a new iPhone project, and worked through a couple hundred compiler and linker errors. At that point it was running in the simulator, but it was only displaying white… After a bunch of unfortunate mishaps, we finally figured out that the problem was the iPhone only supports power-of-two textures (16×16, 32×32, 64×64, etc.), and the game wasn’t properly detecting that. After that was fixed up, I got MakeGho, our Finnish math-slave, to figure out how to rotate the whole thing so that it would be horizontal instead of vertical (SDL doesn’t support doing that itself). We had some graphics artifacts, due to scaling, which Dave fixed up, and at the same time Guido made some controls, which I put in. Last night I put the finishing touches on the controls, bringing us to the stage where the game should actually be playable on an iPhone! I can’t test on my iPod, because I haven’t gotten a dev account yet, but I’m in the process of doing that. For now, here’s a screenshot of it working in the iPhone Simulator:
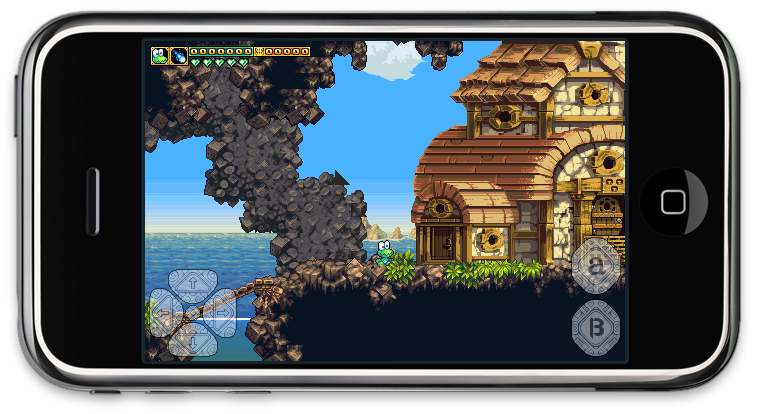
At this point, there are still some things that should be done for the iPhone (mainly re-implementing sound, which had to be disabled due to SDL_mixer not supporting the iPhone), but we should definitely be able to release an iPhone version at the same time we release the mini-saga for PC.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
There’s a new, big setpiece for the world-1 environment: frogatto’s house. We’re working on a few others in the style to take care of the town and nene’s house. We’ve also updated most of the world-1 levels to actually use the new tileset; it practically feels like a different videogame now (in a very good way).

There’s also the beginnings of a cave tileset being worked on. This is the interactible foreground tileset (sans several necessary transitions); we still need a background tileset, and a scrolling parallax background in order to get something we can really make levels out of.

Last but not least, we’ve been working on redesigns of most of the monsters. If you’ve played the latest builds, you’ll have seen the redo of the ants thus far, but here is a preview of a bunch of the other ones yet to come. As you can see, there are several designs that have no analog in the current set; I’m not going to spoil the surprise of what they’re like ingame. 😀
These are being animated and scripted as we speak; expect to see them trickle into the game, one by one.

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The C++ Standard Template Library (STL) contains a powerful set of data structures and algorithms. However, they are often misunderstood. I think to be an effective C++ programmer, one has to understand how the STL works, and so today I’m blogging about how its most commonly used component, vector, works. My explanation is more oriented toward the practical, and typical implementations, rather than the weird corner cases that the C++ Standard might allow.
What is a vector? It is a dynamically allocated array of elements. Whenever you want an array in C++, a sequence of elements, vector is probably what you want to use. However, this post isn’t meant to be too remedial. I’m going to assume you’ve used a vector once or twice before, and step in to show you how it works, under the covers. Once you understand vector thoroughly, it is much easier to understand the operation of other C++ components.
Let us take a simple example:
vector<int> v;
v.push_back(4);
v.push_back(3);
v.push_back(8);
v.push_back(5);
v.push_back(2);
There, we started off with an empty vector of integers, and then added some numbers to the vector. Now let’s look at how the vector represents this in memory:
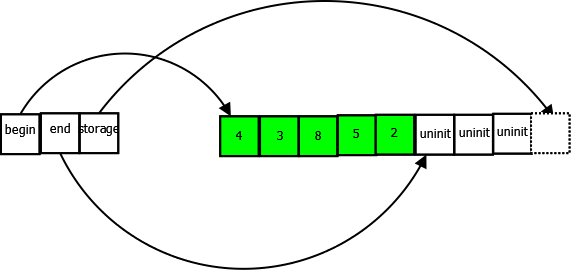
On the left, we have the actual members of the vector object itself, three pointers, begin, end, and storage. On the right we have a dynamically allocated buffer that the vector stores its data in. It’s important to understand what these three pointers are, so I’ll explain them:
Note carefully the pointers that point one past the end. This is a common idiom in C++ and the STL in particular.
Note that a vector always has exactly one buffer that it stores all data in. (Exception: an empty vector won’t have any buffer at all). Note how we have put five integers in our vector, but the buffer has room for up to eight. Each time we call push_back(), adding a new element to the vector, the end pointer will move one step forward.
What happens when our buffer runs out of space to store new elements? A new buffer will be allocated, twice the size [1] of the old buffer, all of our elements will be copied into the new buffer, and then the old buffer will be destroyed. Suppose on our vector from above we now made the following calls:
v.push_back(9);
v.push_back(10);
v.push_back(12);
Here is what our vector looks like now:
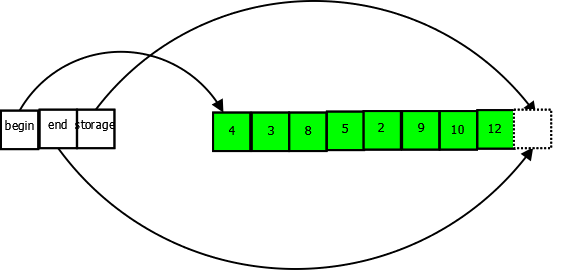
The vector is now at full capacity, end == capacity. The vector cannot perform another push_back in the current buffer. But suppose we push_back() nevertheless:
v.push_back(1);
The vector will allocate a buffer of size 16, and copy all elements to the new buffer, releasing the old buffer.
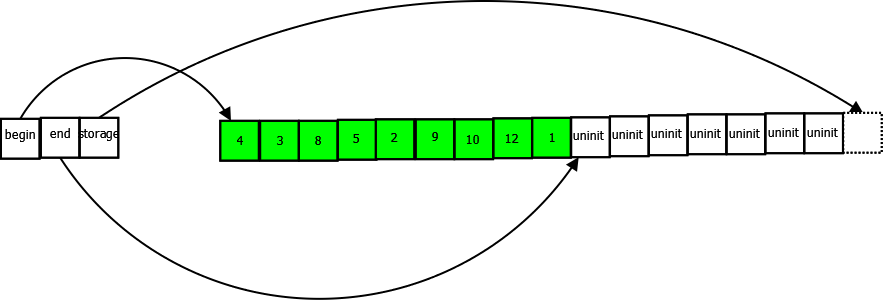
This process can, of course, continue indefinitely. A vector can grow to any size, constrained only by available memory and addressability.
Now, let’s talk about performance for a moment. Intuitively, to many people, vector is not very efficient. Every time its buffer runs out of space, it has to copy all of its elements over, and this means if you’re adding a lot of items to your vector you’re going to do a lot of copying of buffers, and this is going to be terrible for performance, etc etc.
In actual fact, it’s not nearly as bad as most people intuit. To begin with, let’s think about how many elements the vector will be unnecessarily copying. Suppose you grew a vector to the size of 1024 elements, your vector’s buffer would be full. Now add another element, and the vector has to copy its buffer of 1024 elements over. Additionally, on the way to growing to size 1024, you had to copy as many as 1 + 2 + 4 + 8 + 16 + 32 + 64 + 128 + 256 + 512 = 1023 elements. So, to grow to 1025 elements, the vector has to make as many as 1023 + 1024 = 2047 element copies in overhead. More generally, if you grow your vector to size N, the vector might be making as many as 2*N element copies when it reallocates buffers, and on average will make 1.5*N such element copies. Note that the key to all of this is how vector grows exponentially. If you implemented vector by simply adding, say, 128 elements to its buffer every time it has to resize, instead of doubling its buffer, then the number of copies and performance would be terrible.
Is this really very bad? Actually, almost certainly not. Unless you are storing a bulky object that is expensive to copy in your vector, the copying overhead is likely trivial in comparison to the performance benefits of vector.
Formally, calling push_back() on a vector runs in O(1) amortized time. What does the amortized bit mean? Usually if you push_back() on a vector, it’s a trivial operation, that is clearly O(1) time. But occasionally it has to resize its buffer, and that takes O(N) time. However, if you amortize the cost of the buffer resize over subsequent operations, the average is still O(1) time. This generally means you can consider a vector’s push_back() to take O(1) time, however, there are occasional cases where it could hurt you. Suppose you were storing a huge vector — to build up a record of a player’s stats for instance — and suppose this vector was appended to every game cycle. Once it grew sufficiently large, the push_back() might actually take a significant amount of time. This might cause occasional delays in gameplay. In such a case, it would be a good idea to use another data structure, such as a deque. This problem is very rare in practice, though.
This does bring us to an important topic though: What should you store in a vector? Built-ins like integers can be stored easily, of course. But what about objects of class type? Suppose you are programming a particle system and have a particle class, and want to store a long list of particles, what is the best way to do it? One way is to store a vector<particle>, another is to store a vector<particle*>
— that is, don’t store the particles themselves directly in the vector, but store pointers to particles.
How do you choose which? Generally, the larger and bulkier the object is, the more likely it is you want to store pointers to it, rather than the object itself. Storing a vector<int*> would be very inefficient, since the pointers would be as large or larger than the integers and you’d have to have the overhead of the memory allocations too. But for a large object, like Frogatto’s custom_object class, a vector<custom_object*> is probably what we want. Note that to store an object directly, it must be copyable, i.e. have accessible copy constructors and assignment operators.
Note also that if you store a vector of pointers, the vector will not manage the memory pointed to by the pointers. If you want the object’s memory to be managed for you, you could use a vector
<boost::shared_ptr<particle> > to have a vector of ‘smart pointers’ that manage the memory they point to.
Now, let’s move on to some more things you can do with a vector. Let’s look at how we would iterate over all the elements of our vector and sum them up:
int sum = 0;
for(vector<int>::const_iterator i = v.begin(); i != v.end(); ++i) {
sum += *i;
}
Now what is this ‘vector::const_iterator’ thing? Well, an iterator is a concept the STL introduces, intended to generalize the concept of a pointer. A pointer works well for moving over elements, inspecting them, modifying them, etc, but only if your underlying storage is an array — a flat buffer of data. If, in C, you wanted to iterate over a linked list, for instance, you’d likely have to write a loop that looks something like this:
for(node* ptr = list->begin; ptr != NULL; ptr = ptr->next) { ... }
…and then differently again for a data structure like a deque, and so forth. An iterator is a type that looks and behaves like a pointer, providing either all of a pointer’s operations, or at least a defined subset of them. The idea of an iterator is to allow access of members of a data structure using a uniform syntax, regardless of the data structure’s underlying implementation.
Thus, just think of a vector::const_iterator as behaving exactly like a const int* does.
Another important concept to understand regarding vector is known as iterator invalidation. Remember how when we push_back() on a vector, and it runs out of space, it’ll reallocate the buffer? Think about if you had a pointer to one of the elements within the vector. That pointer would now point to the old buffer, the one that has been destroyed.
In C++ terms, calling push_back() on a vector invalidates all iterators into that vector. Once you call push_back() all iterators you have into the vector are unusable, and the only thing you can legally do with them is reassign them to a new value. Reading or writing to the iterators may cause the program to crash, or a host of other nasty behavior.
This effect can be rather subtle. For instance, we had code something like this in Frogatto to detect collisions between objects:
for(vector<object_ptr>::iterator i = objects_.begin(); i != objects_.end(); ++i) {
for(vector<object_ptr>::iterator j = objects_.begin(); j != objects_.end(); ++j) {
if(i != j && objects_collide(*i, *j)) {
handle_collide_event(*i, *j);
}
}
}This code iterates over every object pair to see if there are collisions. Simple enough, right? Now what if inside an object’s collide event it spawns some new objects, and that spawning adds the new objects to the objects_ vector? Then the objects_ vector’s iterators are all invalidated, including i and j. We are still using them in our loops though! To make matters worse, it only occurs if the new objects happen to trigger a reallocation of the buffer.
Note that you can iterate over a vector using indexes, which a lot of people find easier/simpler than using iterators:
for(int i = 0; i < v.size(); ++i) {
...use v[i] instead of *i...
}
This has similar performance, but note it’s less general. You can’t use this approach to iterate over most of the other STL containers. In Frogatto, we have a foreach macro we use for most simple iterations.
So far we’ve covered growing a vector using push_back, and iterating over it. Let’s look quickly at the other operations vector supports:
Remember that vector represents a contiguous buffer. If you want to erase an element in the middle of the vector, all the elements in front of the erased element will have to be shuffled back.
As an example, suppose you had a vector of particles, and wanted to remove all of the ones that have expired. Do not do this:
vector<particle>::iterator i = v.begin();
while(i != v.end()) {
if(particle_expired(*i)) {
i = v.erase(i);
} else {
++i;
}
}
Note that this code does do the correct thing. erase() will invalidate the iterator being erased, but it will return a valid iterator to the next element. The loop carefully moves over all particles erasing the expired ones. But the performance of this is potentially terrible. Suppose we had a million particles in our vector, and they have all expired. We’ll be doing around half a trillion particle copies, just to empty out our vector!
So how should we do this? There is an algorithm supplied in the STL designed to do exactly that, called remove_if. This is how you do it:
vector<particle>::iterator end_vaild = remove_if(v.begin(), v.end(), particle_expired); v.erase(end_valid, v.end());
How does this work? Firstly, all of the STL algorithms operate on iterators not on containers. If they operated on containers, you’d have to have a version for each type of container. So, the remove_if algorithm takes an iterator to the beginning, and then to the end of the sequence we want to operate on. It also takes the function to call on each element to see if it is to be removed.
Remove_if efficiently shuffles all elements that should not be removed forward, overwriting elements that should be removed. At the end of the call to remove_if, all the remaining elements are at the front of the sequence. Let us illustrate this with an example, suppose our vector contains particles with the following ID’s:
[4, 8, 2, 12, 19, 3, 7, 18]
Now suppose all particles with ID’s lower than 6 are being expired. After the call to remove_if, our vector will now contain this:
[8, 12, 19, 7, 18, ??, ??, ??]
See how everything less than 6 has been removed. Everything over 6 is now at the front of the vector, with the order maintained. However, the size of our vector hasn’t changed — because remove_if only has access to iterators, and iterators can’t change the size of the vector they point into — now at the end of the vector are some ‘garbage’ undefined values.
Fortunately, remove_if provides a convenience way to resize the vector and remove the garbage. It returns an iterator to the end of the valid values. So we use this iterator to remove all the invalid values at the end, with our erase call.
One final operation vector has which I want to talk about is swap(). You can call swap() on two vectors and they will be efficiently swapped. That is, they will simply swap the pointer values they have. This is useful in a variety of situations, for instance to ‘move’ a vector into a new location without the expense of a copy. Also, we have discussed the way a vector grows its buffer. Yet if you call shrinking operations such as resize() with a smaller value or pop_back() or even clear(), a vector never shrinks its buffer. So if you call push_back() a million times on a vector, then call clear(), the vector will still hold a huge buffer of memory. This is probably a reasonable decision, since any shrinking would risk pathological situations where a vector keeps growing and shrinking its buffer. However, it is useful to be able to shrink a vector by hand. Here’s a way you can manually clear a vector, so it has no buffer at all:
{
vector<int> tmp;
tmp.swap(v);
} //tmp is destroyed here, taking the swapped buffer with it.
There’s a lot more to understand about vectors, and all their implications. Hopefully this gives a good overview. Unless you have a very good reason not to, vector is generally the best container to store things in in C++. It is efficient and compact, and generally gives the best real-world performance of any container.
[1] Actually, the C++ Standard only requires that a vector grow exponentially, it doesn’t specify the exponent. So a vector could make its new buffer four times the size of its old buffer, for instance, or one-and-a-half times. But all implementations I know of double it each time.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Since the first versions of frogatto, an implicit part of The Plan™ has been to do the tile graphics in a somewhat simple, cartoonish style. This was for a bunch of reasons, but it was generally to make it easier. Easier in terms of simply being less work. Easier in terms of ‘not requiring more skill than we have’. Easier in terms of just being clean by default, since geometric, cartoonish shapes tend not to have odd tiling errors which more erratic styles of organic patterning tend to cause.
You’ve seen this art in both major revisions of frogatto’s graphical style; both the really early test tiles, and the current stuff that’s been holding us for essentially the whole lifetime of the project. And we’re now taking it to the chopping block.


We’ve decided to completely change this part of the plan (for our tile art). The crux of this was a motivational problem. Neoriceisgood and I are both rather good sprite artists by now, and the simple art we were hacking on was neither challenging to do, nor was it something we could really be proud of. If we have the skill, and are spending a year or so on the project anyways, we may as well do the best job we can. Especially when, although the art cost per major environment mushrooms a bit (2-3 weeks versus 1 week), the entire rest of the game project is essentially the same in manpower costs. Levels don’t take any longer for us to design (due to our autotiling system, which I’ll describe in another post), the code is mostly done at this point (pareto principle notwithstanding), and the object scripting doesn’t change at all to accommodate this.
It will take more time, and this is normally a Very Bad™ decision in a game development project, but we’re not on a fixed budget, we’re skilled enough to do it, and it’s necessary for this to be something we were proud of having made. If there’s a purpose to approaching these projects from an ‘indie’ direction, having the liberty to do it right is foremost.
At the current point in time, we’ve basically overhauled all the art for both the world-1 environment (which has changed to a background of ocean, rather than light forest), and most of the world-2 deep-forest environment. We still have a good bit of work to do to catch up; we need to overhaul the dungeon environment, and we need to provide interiors for world-1, but we’ve tested the waters on this, and I think this is a sound plan going forward. Here are a few screenshots:



![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
People who are familiar with any of my projects probably know that I am not always fond of using existing tools and libraries, often preferring to implement things myself, for one reason or another. This is particularly so if I feel a certain library imposes a significant intellectual burden in understanding its workings, while some hand-written code tailored to the purposes of the project could have much less intellectual burden.
I’ve used a few popular unit testing frameworks, such as cppunit, and found them generally cumbersome. I hate having to write an entire class to write a unit test, with a bunch of boilerplate code for each test. I must admit to not being entirely aware of all the benefits of using a unit test framework. I know that some frameworks give support for mocking and stubbing objects out and so forth, but, well, that all sounds like far more burden than it’s worth.
So, in Frogatto I have implemented a super-simple unit testing framework. If you want to write a unit test, then in any Frogatto source file, just include unit_test.hpp and add some code like this:
UNIT_TEST(simple_arithmetic) {
int x = 4;
x += 8;
EXPECT_EQ(x, 12);
}
That’s all a test takes! Just write UNIT_TEST(name_of_test) and then a code block with your testing code. When you’re ready to see if your test ran as expected, you can use the macros provided, EXPECT_EQ/NE/GT/GE, etc etc to see if values came out as you expected them too.
Then, when you start Frogatto, all tests are run automatically, every time! The program will die with an error message if any tests fail. This forces and guarantees that people will not check in code with broken tests, because if they do, it’ll break the game horribly.
This is what unit tests should be like, in my view, very simple, easy to write, and easy to run. I’ve worked at too many places where some Agile fanatic tells everyone that they should write unit tests to test every single bit of code and are willing to discuss the joys of testing for hours on end with all the nuances of how many different code paths you should test, and then want you to learn some framework that they can understand very easily because they are interested in unit testing, but which everyone else who just wants to write code finds to be a burden to learn.
Sure, unit testing is a good idea, but to be workable it has to have minimum overhead. That is the aim of Frogatto’s framework.
The second part of Frogatto’s framework involves performance testing. If you’re writing a piece of code and you think its performance is going to be important, or if you have a piece of code and you know it’s taking up a significant amount of time, it’s nice to have an isolated test to verify that. So, the unit testing framework provides a benchmarking system.
Let’s see an example of how to add a benchmark. I wanted to benchmark how long it takes to query and convert a WML attribute into an integer, so here’s my benchmark:
BENCHMARK(wml_get_int) {
wml::node_ptr node(new wml::node("a"));
node->set_attr("abc", "47");
BENCHMARK_LOOP {
wml::get_int(node, "abc");
}
}
This declares the benchmark with its name, and sets up some test data. Then the code inside BENCHMARK_LOOP is the part we actually want to benchmark. The benchmarking framework will run this part an appropriate number of times. So if the code takes a second to run, it’ll only be run a few times, and that averaged. If it takes a few nanoseconds to run it’ll be run billions of times, and that averaged.
How does a benchmark get run? Unlike unit tests, we don’t want to run benchmarks every time we run Frogatto, because that’d slow down startup and most people would just ignore the results. Instead, you run Frogatto with the –benchmarks argument. Frogatto will run all benchmarks with a report, and exit. You can also provide a comma-separated list to –benchmarks of the names of the benchmarks you want run. e.g. –benchmarks=formula_load to only run the ‘formula_load’ benchmark.
Output of the benchmarks framework looks like this:
BENCH wml_get_int: 1000000 iterations, 341ns/iteration; total, 341000000ns
This shows us that our wml_get_int benchmark ran for a million iterations, and each iteration took 341ns. So, it takes 341ns for us to get an integer from a WML node. Being able to work with and quickly intuit time periods is important in performance analysis. It takes 341ns to extract and parse an integer from a WML node. How significant is this? For one thing, we could find the wml::get_int() function and put a counter in to see how many times it is executed in a typical load of Frogatto. However, my guess is that even in a long game we’d parse less than 100,000 integers. This would make this function take up only around 34ms per run, which really isn’t very much.
On the other hand, 341ns seems like a lot to me to parse an integer. Of course, this code also extracts the integer, which requires a map lookup, and string construction, and so forth. If it turned out to be important to optimize this code, we probably could.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The way that memory is allocated and used is an oft-misunderstood topic. I’ve never found a satisfactory yet simple reference of everything a programmer should know about it, so here is my feeble attempt to write one.
Modern Operating Systems use a memory management design known as virtual memory. This is a very oft-misunderstood term, even amongst experienced programmers. If you think that virtual memory is “when hard drive is used as memory” then you need to read very closely, because that definition is completely wrong, and it will remain wrong regardless of how certain Operating System vendors choose to label their interfaces. 🙂
Virtual memory is a memory architecture where processes are presented a view of memory as a single flat address space, when in fact the data may be stored in one or more physical devices, or in some cases, not stored at all. Using hard drive in lieu of memory is known as “swapping”, and virtual memory is nice because it enables swapping easily in a transparent manner to a programmer. There are plenty of benefits to virtual memory that have nothing to do with swapping, though.
One of the big benefits of virtual memory is that each process gets its own address space to play with. It is not possible for one process to access another process’s address space, because the OS maintains a table for each process which shows which addresses map to what physical storage for each process. So the address 0x00FABE0F20 will likely refer to one piece of physical memory in one process, and a completely different piece of physical memory in another process.
Memory is divided up into pages. A page is typically 4KB, and rarely less than 4KB, though some systems use (much) larger page sizes. When a process wants memory, it must use a system call to allocate one or more pages. This is typically the mmap() system call on Linux. The Operating System will set up a mapping, allocating an address range in the process’s address space.
The Operating System is responsible for choosing how to physically store the data represented, and will do so in the most efficient way possible. Each page will be stored in one of three possible ways:
(1) unmapped: if the program has not written to the memory region since requesting its allocation, then it is by definition filled with all-zeroes. The Operating System does not have to store it at all, since it knows it’s just filled with zero bytes. Thus the OS will just mark the page as ‘unmapped’ until the program actually writes to it. Thus, on most Operating Systems, when you allocate “memory”, the OS will give you an address range but won’t actually map it to physical storage (yet).
(2) resident: the page corresponds to a page in RAM.
(3) swapped: the page corresponds to a page that has been swapped to disk.
It is quite important to understand the implications of (1). For instance, in C++ it is common to use the std::vector class template as a dynamic array. std::vector over-allocates memory so that it doesn’t have to expand its buffer too often. This may seem expensive, but for a decent size std::vector, you don’t actually pay in terms of physical memory until you start using the memory.
For most typical programs these days, it’s actually common for between 10% and 50% of memory to be in state (1). State (2) is the next most common, and most people hate it when things start getting swapped, so (3) is relatively rare.
Let’s look at what top has to say about Frogatto’s memory usage:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1427 david 20 0 119m 76m 17m S 22 2.5 0:02.70 frogatto
VIRT refers to the amount of address space that Frogatto is using. i.e. the amount of memory that is in states (1), (2), or (3) above. RES refers to the physical memory that Frogatto is using. i.e. the amount of memory that is in state (2) above. As we can see, Frogatto has allocated 119MB of memory, but only 76MB is resident. Unless we have a good reason to think swapping has occurred, our best guess is that the rest is in state (1) above. So Frogatto has allocated 119MB, but only actually started using 76MB, and so the Operating System has only needed to actually allocated 76MB worth of physical memory for it.
It should be noted that on a 64 bit system, VIRT is not a very constrained resource. The address space is huge, and so VIRT can grow almost without bound. Most OSes will reject allocations that they consider ridiculously above the amount of physical storage space, though Linux at least can be configured to allow any allocation.
On a 32 bit system, each process can generally only allocate 2GB of virtual memory, due to lack of address space. This makes VIRT still a rather constrained resource for many applications — though for desktop applications, 2GB is still considered a very large amount of memory, and most servers are moving toward 64 bit architectures.
Now, what is this “SHR” thing? It is how much memory is “shared”. Another feature that virtual memory facilitates nicely is making it so a virtual address range in use by one process happens to map to some physical memory that a completely different virtual address range in a different process also maps to. Some programs do this explicitly, as a communication mechanism — a very fast communication mechanism for that matter — however the most common reason this is done is by the OS itself as an efficient way of storing shared libraries in memory. It is common for a shared library to be used by many programs that are running at once, and rather than storing a copy of the shared library for each program, the OS will store it just once, and map each process to it.
Since we know that Frogatto doesn’t do any explicit sharing, this tells us that at least 17MB of Frogatto’s memory usage is due just to libraries. Being shared memory, it means that even if Frogatto wasn’t using this memory, another process would be, so Frogatto is actually only adding 59MB, not 76MB, to the system’s usage of RAM.
You can actually break down all the memory usage of a program using a cool little command called pmap. Running pmap on Frogatto gives output that looks like this:
08048000 2132K r-x-- /home/david/frogatto/frogatto 0825d000 4K r---- /home/david/frogatto/frogatto 0825e000 4K rw--- /home/david/frogatto/frogatto 0825f000 8K rw--- [ anon ] 09218000 31400K rw--- [ anon ] b288f000 2048K rw-s- /dev/dri/card0 b2a8f000 1024K rw-s- /dev/dri/card0 b2c90000 772K rw--- [ anon ] b2d52000 2004K rw--- [ anon ] b2f48000 3500K rw--- [ anon ] b32b4000 1936K rw--- [ anon ] b3499000 2476K rw--- [ anon ] b3705000 1032K rw--- [ anon ] b3807000 4K ----- [ anon ] b3808000 8192K rwx-- [ anon ] b4008000 12K r-x-- /usr/lib/alsa-lib/libasound_module_rate_speexrate.so b400b000 4K r---- /usr/lib/alsa-lib/libasound_module_rate_speexrate.so b400c000 4K rw--- /usr/lib/alsa-lib/libasound_module_rate_speexrate.so b400d000 64K rw-s- [ shmid=0x5c8016 ] b401d000 84K r-x-- /lib/tls/i686/cmov/libnsl-2.9.so [snip]
This shows us the starting address of the mapping, the size of the mapping — which is always a multiple of 4KB on this system with 4KB pages — the permissions of the memory, and then the underlying device.
On Linux, files may be “memory mapped”. That is, a file loaded into a segment of memory, with modifications of that memory modifying the underlying file. This is very different to simply reading a file into memory; the memory becomes an actual representation of the file that the kernel maintains. We can see that the Frogatto binary itself occupies several megabytes, as do various libraries. The most common use of memory mapped files are to access executables and shared libraries, though it is possible to map any file into memory.
The [ anon ] mappings are requests the application has made for “just plain memory”, not mapped to any file. This is the most common form of memory an application obtains.
For most applications, getting memory in multiples of 4KB isn’t very convenient. Most modern applications tend to allocate very many objects, of varying sizes, most of which are far smaller than 4KB. So, most programming frameworks have an additional memory management layer which will allocate memory from the Operating System, and then carve it up into smaller and different sizes for the application to use. In C, this is usually malloc() and free(), and in Java it is the memory management/garbage collection system provided by the VM.
Because memory is allocated in chunks of at least 4KB and then carved up, it is very difficult for a program to release memory that it has allocated back to the Operating System. A page might be carved up into 40 or 50 or 100 different small allocations, and every one of these would have to be released for it to be possible to release the memory back to the OS. For this reason, most programs stay at or near their high water mark in terms of memory usage.
Most memory allocators tend to satisfy large allocations by calling the OS directly. For instance, it is typical in dlmalloc() — one of the oldest allocators that many modern ones are derived from — to implement malloc() calls of 64KB of more as a direct call to mmap() on Linux, and then call munmap() when free() is called.
This has advantages, though it also has disadvantages. Generally if one accesses memory — or at least writes to it — it must be resident — i.e. in state (2) above. If the memory is actually in state (3), swapped, then it must be copied from disk to RAM. This is called a major page fault, and is terrible for performance. However, even if it’s in state (1), unmapped, the kernel must still spend time allocating it to physical RAM. This is called a minor page fault, which isn’t near so bad as a major page fault — indeed typically several thousand times faster — however nevertheless, if your application regularly allocates and uses large buffers of memory, it might be better to consider caching the buffers than continuously allocate and deallocate, since every new allocation of a buffer will trigger a new round of minor page faults when you start using the memory.
The way in which the kernel allocates memory also has a somewhat unfortunate effect on the behavior when memory exhaustion occurs. The C memory management system was designed so that malloc() returns NULL if the memory couldn’t be allocated. However, unless you try to allocate something truly ridiculous, or run out of address space on a 32 bit machine, malloc() will almost certainly succeed on a modern OS. Instead what will happen is that when you actually start using the memory, the minor page fault will be unable to be satisfied, and the OS will kill your application. That is, if the user didn’t become sufficiently frustrated with all the swapping to kill it first.
Another feature of the way Operating Systems use memory is the filesystem cache. If you’re developing an OS, you know it’ll improve performance to use some memory to cache filesystem accesses, but how much do you use? Simple: use all the memory that applications aren’t using. This is how Linux and most other modern OSes do it. Let us look at the output of the free -m command:
total used free shared buffers cached Mem: 3030 2948 82 0 222 1332 -/+ buffers/cache: 1392 1637 Swap: 4110 547 3563
At first glance it may appear that this system has 3030MB, is using 2948MB, and only has 82MB available. However, 1332MB are ‘cached’ — that is, being used for filesystem cache. 222MB more is being used in kernel buffers. If applications start using more memory, the OS will generally rather happily allow their requests to be satisfied by shrinking the size of the filesystem cache.
Thus for all intents and purposes, it is recommended to use the -/+ buffers/cache line and say that this machine is using 1392MB, and has 1637MB free. The OS uses the filesystem cache to fill up memory that isn’t otherwise being used, but usually prioritizes application storage over it.
I say “usually”, because Linux and other OSes sometimes decide that certain memory allocated by applications is being used very infrequently, while the filesystem cache is being put to good use, and actually swap out some portion of applications in favor of keeping more space for filesystem cache. Whether this is a good idea is sometimes debatable, but filesystem cache can indeed speed up the performance of many systems.
Speaking of swap, it is important to understand that swapping out generally isn’t very expensive. It can be done in the background. What is expensive and kills performance is only if memory that is swapped out is accessed and needs to be swapped back in. This generates major page faults — accesses to memory which require reading the page that memory resides in in from swap. This is usually especially terrible because if you were, say, traversing a linked list, each node in the list might reside in a different page, meaning you will have repeated page faults, and each time you have to wait for the page to be loaded before you can work out where the next node is.
So we’ve talked about various kinds of faults. Another popularly known fault is a segmentation fault. What is that exactly? Generally it occurs when a program tries to access a memory address that is not in the kernel’s table of mappings for that process, or if it accesses a page that is in the table of mappings, but does so in a way that it doesn’t have permission for. For instance, in the pmap output above, we can see that executables and libraries do not have write permission in their mappings.
Understanding how memory works gives us a better understanding of how buggy C programs will behave. Suppose you malloc() a buffer and then write to that buffer, overrunning it. It is possible that your overrun will end up straying into a page that you don’t have access to, though this is relatively unlikely. More likely is that you will simply overwrite some part of your own program’s memory that you didn’t intend to. However, it is quite likely that you will overwrite the value of a pointer, and the new value you write in the pointer will not correspond to a valid address in your application. Next time that pointer is dereferenced, you will have a segmentation fault.
Hopefully this article gives a good overview of how memory works from an OS and performance perspective. I welcome any comments or suggestions.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()