Frogatto & Friends is an action-adventure platformer game, starring a certain quixotic frog.
We're an open-source community project, and welcome contributions!
We also have a very flexible editor and engine you can use to make your own creations.
At long last, we’re pleased to announce the release of Frogatto version 4, which is immediately available on Steam. We’d like to extend a huge thanks to all of the contributors who made this possible, and helped us through the long-haul to get this release out — Thank you!
This release features major additions to the game — we’ve almost doubled the total number of levels, including many new “secret levels” you can find along the way, as well as adding dozens of new enemies, three major new actbosses, and a total remaster of most of the animations in the game as well as large parts of the scenery art.
We’ve got an exciting roadmap of future releases planned, which we’re intending to release on a much faster cadence of “every several months”. Future plans involve enhancing a bunch of enemies to be much more cunning opponents, adding numerous puzzle elements to levels that don’t have them, and doing a major overhaul of player abilities and quest items.
Thanks for tagging along with us on this journey, and we hope to have lots more excitement in the time to come!
On 2020-06-19, UbuntuJackson laid down a very impressive speedrun, beating Frogatto in 19:36.21. Around the our virtual water-cooler, we all agreed that we were quite impressed!
As a developer, watching a speedrun of your own game is both humbling and inducing of a feeling of incredulousness. “How could we create this little content, yet include so many bugs?”
It also raises the question of what to do about the bugs. A developer of the game is both a tremendous asset and huge risk to a speedrunning community. When a run comes to the developer’s attention, critical bugs tend to get fixed and run times go up. Sometimes, the reaction of the community has been to run on early builds of the game, canonicalizing the release-day disk as the version the run is built on. (This is often a lot harder with heavily DRM’d games, as you have a much more tenuous ownership of them and can only play the most up-to-date version.) Other times, the community will shrug and move on, accepting a slower patch for stability and bifurcating the leaderboards to reflect this. With Frogatto, we are lucky in that we are a very traditional single-player game with no DRM. We do not have to patch exploits or force people on to the latest version.
So what about the issues UbuntuJackson has showcased for us? Some are fixed in the next release already. Some have simply gone away, as we replace older content with newer. The next version introduces two new act bosses; so we definitely don’t have to worry about keeping the times the same! So, we have to take a hand-off path; to marvel how broken our game is, and be honoured by the attention that has been paid to break it.
We look forward to seeing what merry havoc will be played with our next release.
Hi folks, Hunter here. We’ve been working hard these past several months on getting the next version of Frogatto & Friends finalized and ready to go. We’re not in development hell. Hell, we’re not even in development purgatory. Our only excuse is that we’re a small group of folks all working on this project, and updating our website with new content is more of a way for us to say “hi, we’re not dead”.
There’s some pretty significant stuff headed your way soon as we put the finishing touches on the upcoming release. In the meantime, however, we wanted to extend an open invitation to our official Frogatto Discord server! We’ve found that It’s a lovely utility for communicating both with fans and other developers. Since we keep a pretty open channel about our practices and overall development, it strikes a nice balance that’s just right for us. You should also check us out on Twitter for more juicy updates.
So there you have it. Bottle up your formaldehyde, put away your science textbooks and stow those scalpels somewhere else, ‘cause this frog ain’t dead yet.
Here’s a preview of our lovely new boss, The Iralchtahne of Essikoria. “What?”, you’re saying. Then the Iralchtahne says nothing.
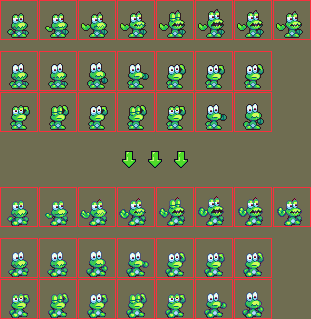
It’s been a slow month here. The only major news is that Jetrel has been working on cleaning up and polishing Frogatto’s (the eponymous main character’s) graphics. Here’s a recent example:
The onion skin view on github helps highlight the differences.
A huge part of this has been an ongoing effort to redo Frogatto’s core movement animations – some months earlier, he had taken on redoing our running, walking, and jumping animations, and now at long last, it was time to take on swimming (which was a lot more complicated because of the need for separate animations pointing in different directions – the others were able to get by with one mirrored animation facing to the side). This was recently finished up about a week-and-a-half ago. This is a gif showing what it looked like beforehand:
And here’s an animation of what it looks like now:
I myself have been struggling with our build system, and have been unable to build Frogatto for several weeks now. (I can’t get Frogatto to run on Ubuntu, since I’ve messed up something up dependency-wise.) Because of this, there has been no progress made on the inventory screen.
With one notable exception, the last few weeks have been a lot of odds-and-ends; the less exciting bucketload of piecemeal feature completion that leads to working software. (Added a few objects, fixed some bugs, made some other objects work right, etc…)
The big item, though, is something we can fortunately show off here in its partly-complete state; most of the art for this is done-ish, and most of the code is a little over halfways there (the difficult parts have been broken down, but there’s still a lot of tedious busywork left to eat up time.
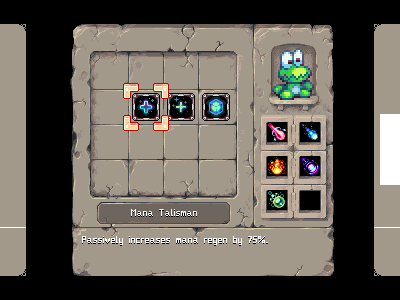
We’re working on a multi-pane inventory/etc screen that pauses the game when it comes up. (If this doesn’t make sense, think along the lines of the 2d “zelda” titles).
This will be broken into multiple, modular panes – basically, we’ll be able to make the different parts of this into items you acquire in the game (for example, there will be a magic ‘automap’ you can get to see the layout of the current level – you’ll actually ‘get’ this as a quest reward, rather than having it from the get-go). Another nice side-effect of this is that if we have additional ideas in the future (or really – as we get the work done) we can slot in whole new panes as we go. We’re planning to have a bestiary that lists out all the different creatures you’ve encountered, and their different vulnerabilities/strengths.
Here’s a shot of what the core screen looks like:
And here’s what the background for the map will look like (we don’t have any of the overlay drawn on this yet).
New enemy:
We came up with this wily fellow. I spent way too much time fighting with this guy’s animations, but I’m quite happy as to how he came out.
We’ve still got a few more enemies planned for in the next release; more enemies for the swamps are definitely going to be a prime focus. This fellow gets us that much closer. 🙂
Compound objects:
The biggest thing I’ve been working on recently has been a system to do compound sprites. Compound sprites are when you use multiple sprites to create the appearance of a single, larger object – in the old days of sega/nintendo, these were just used for size, since even seemingly ‘small’ characters like mario or sonic were actually a multiple of the native square-sprite size of the machine they ran on. These days, we don’t have any meaningful size limitations on sprites, so instead we use compound sprites for positioning or animation. For example, a clock face would easily be done with one sprite for the dial, and separate sprite for the hands – the purpose being that if the clock-hand sprites are separate, you can freely rotate them, programmatically, meaning you can have a full, 360° of rotation without any new drawings being necessary on the artist’s part.
We’ve wanted to have these in the game for quite a while; technically, we’ve been able to do them since the early alpha versions of our engine (Anura), but in practice they’ve been a buggy mess. The system I’ve come up with is no holy grail (there are a number of fancy animation-scripting things that still have to be done by hand), but it’s very, very clean, and should stay fairly bug-free. One of our main goals was to have these sprites, to the player’s eye, seem like a seamless extension of the core object they were a part of. Any damage-contact applied to any part of these should act like they’re one, indivisible object; any visual effects like color-flashing should affect the entire thing, without any inter-frame delays. Chiefly, we’re also worried about orphaning these child objects – if the core enemy they’re attached to, dies, we need to have a reliable system for getting rid of them.
Bug-free designs are really our top priority at this point; we had some compound enemies in the past and I’ve actually ended up mothballing a few of them because it was too much work to keep them running as they broke over and over due to other changes in the game. A tough lesson I’ve learned in game-design has been to resist the siren song of new features that I can’t quite come up with a rigorous way to handle; they might not take any longer to prototype than anything else, but I can’t treat a working prototype as a “bird in the hand”. I have to treat the real cost of features as the full, lifecycle cost of all the future bugs its going to incur as it interfaces with other elements in the game. Thus, I need to focus on things that have a way lower lifecycle cost – which is usually down to ‘devil in the details’ planning of how they work. It’s less about what I do, so much as it is about holding off unless I’ve got a really clean way to do something. There are plenty of “cool 2d platformer tropes” we’re leaving on the shelf unless they can meet this requirement, but the result is we’ll actually ship the damn game, so it’s a small price to pay.
As for the new compound-object system; there are several specific things that finally made it viable. Most of it had to do with some major, structural improvements to our “hittable” class (a long, ongoing project over the last year or so). Most of these have been down to a transition away from a type/recipient-blind “event-driven” system, and instead moving to a pure-functional, strict typed means of triggering behavior. A lot of this has been enabled by some huge upgrades to Anura’s scripting language, making it strictly typed – most especially with regards to non-null containers, and object access – we now can have hard, static-analysis guarantees that if we’re operating on some set of links to other objects (like, say, compound object parts) that we’re guaranteed to be pointing at a real, object, and not something that had been deallocated earlier. A big benefit here is that our hittable code has a very limited set of entry points; we’ve got one place where hit-triggering behavior gets captured, and this can safely redirect calls for being hit to a parent object (and thus make sure the full suite of damage-receiving code gets triggered correctly).
Hopefully this will bulletproof the few enemies we have based on compound objects, and let us gradually ease into doing more in the future.
We’ve been making some update posts over on our steam greenlight page for a while now, without cross-posting them here. I’m going to start backporting a few of them to here, and try to keep up with consistently cross-posting them in the future.
New flight animations:
A long-running project we’ve had going has been upgrading the animations on all of our older monsters. New monsters we’ve been making from scratch have high frame counts from the get-go; we had several older creatures which didn’t (In the pending release, we’ve just about doubled the number of creatures in the game).
Like a lot of indie game projects, frogatto has been one of those where we’ve been “learning as we go” – our older art was cheaper because my skillset was a lot weaker when I made it. Two of the points of cheapness were that most of the animations had a very low frame-count (about 3 or 4 frames for most “cyclical” animations like walking and flapping), and most of the old monsters were “clones” of each other – they were a similar base body design, recolored, with a few cosmetic bits tweaked to make them look “different enough” whilst allowing most of the animations to be copy-pasteable (with similar recoloring tricks, etc).
The problem with cloning like that is it becomes noticeable after a while – do it too much and even the less aesthetically-inclined players start to notice and it cheapens the experience. Fortunately there were few enough of them that I don’t think we need to actually rip them out – instead, we just needed to draw a line in the sand and say “let’s make sure all of the new ones we add are brand-new designs”. The upside of keeping these existing ones is that if I upgrade one of the core animations for them (like the ant walk cycle, or the flying-ant flap cycle), I can copy over the improvements to all of the other clones and get a lot of bang for the buck – get dramatically better animations on a bunch of creatures for fairly little effort.
So in the last few weeks, I took the flying ant’s core animation and applied it to about 4 other creatures which are seen in the seaside chapter of the game, and a couple creatures seen in the cave chapter of the game.
This post has a comparison of our older flap animations against the new ones:
http://steamcommunity.com/sharedfiles/filedetails/updates/181850301/1427435374
New miniboss fights:
I don’t want to give any story spoilers on this, so forgive me if this sounds a bit analytical and antiseptic…
If you’re familiar with the earlier releases of the game, we’ve got one lonely miniboss fight – one stage where you’re locked in a room and have to fight against 4 regular “kitty” enemies. In that particular fight’s case, it’s a fairly easy battle used to introduce one of the main enemy types in the game, and force the player to familiarize themselves with how the enemies work. We’re going to be adding something like 5 or 6 more such fights in the coming release.
I like these because by putting a simple twist on how a creature is presented in its environment, an existing monster’s challenge-factor can be radically changed (A metaphor I frequently use to explain this is that a sniper in the middle of an empty parking lot is a lot less dangerous than a sniper in a cluttered urban setting). Not only is it good for mixing things up gameplaywise, it’s also good for forcing the player to learn-by-doing, and it’s great for narrative cycles; for adding climax and surprise to different chapters of the game. It’s a shame we haven’t done this before; a number of sections we’ve had in the game prior have been completely devoid of boss-fights, and it really made them feel flat. This, as well as the two new actbosses we’ve finished are really going to help spice things up.
So far we’ve got two of these two miniboss fights mostly done, and we’re got a third one well on its way.
Seaside level enhancements:
Some of the earlier seaside levels date back to the beta of the game – they’ve been reskinned as we’ve redone our graphics, but their basic layout remains the game – especially in the flaw of being a pretty straight-shot linear run from left to right.
I’ve gone over a couple of them (the levels “Splash Hop”, and “Burn and Bubble”) and added some major puzzles to them (where there were no puzzles, before), and I’ve greatly increased the size of them, vertically, adding additional paths you can take through the level, each with its own unique challenges. I’m also in the process of re-adding a great old level we used to have called “Stonepipe Flats” which was made during the beta and got dropped for no really good reason other than me being too lazy to reskin it after one of the big graphical makeovers. It’s high time it had a moment in the spotlight, since it’s a fairly nice level with a few good puzzles on it.
Today, we have a shout-out to Tower 57, whose kickstarter badly needs your support with roughly a week left. They’re close to meeting their goal, but your individual support could mean the difference between success and failure for their campaign. Get out there and pledge!
1920s art deco. Dystopian future. Destructible scenery. Tower 57 is a twin-stick shooter where you go on an espionage mission to a rival tower, trying to keep them from declaring war on you.
Work is continuing apace on the next release (version 4) of the game. The two new actbosses for the forest are in place, and we’ve done a bunch of heavy lifting on level (and monster) design for the new forest levels.
We’re working on integrating the new ability system into a much better HUD than we’ve had before – namely, one with an inventory screen (along the lines of, say, 2d zelda games) so you have some idea of which items you’ve acquired, and which will open up some new possibilities for interaction (for example, there was no way under our current setup to have consumable items).
The majority of our work from here on out is polish – we’re trying to re-connect a lot of our levels and allow lots of areas to be present which you can only reach by returning to a place later, with some ability acquired later in the game. There’s going to be a lot of work to this; the main thrust behind this is basically to transform us from a straight-through linear platformer, to what’s commonly called a “metroidvania” (a game with the non-linear player progression of something like Super Metroid, Castlevania: SotN, or Zelda: LttP). That’s not a simple job.
We’ve also been revising frogatto’s own animations, to make his motion much smoother and fluid; we’ve already done this to the walking, standing, and jumping, and we’re hoping to have a go at swimming, before too long. Our hope with the swimming is to keep the controls as they are now (which are fairly satisfactory), but to make the graphics much, much more fluid. This will also pave the way to allow us to add attack modes for the player’s alternate powers underwater.
We don’t have much heavy-lifting left for the graphics. The remaining items are: I have some stand-alone mushroom props I need to draw, I have a few forest-tree trunk segments I want to add to flesh out the flexibility of our tree props, and I need to redraw a few more seaside houses before the next release.
I estimate it’s going to be several months before the next release – we’re all doing this part-time, and most likely the level-design work is going to take quite a while. If you’d like to stay posted on things as they happen; follow our twitter @frogatto, or keep an eye on the recent commits to our github (we tend to make changes on a daily basis).
Hello! My name’s Adam, and I’ve been doing sound effects for Frogatto. About 90% of the sound effects currently being used are fresh recordings by me (the rest are made with bfxr; it’s a lovely program and a quick, easy and free way to get classic “video-gamey” sounds). This is the first time I’ve done sound for a video game, and since the process has been absolutely fascinating for me I thought I’d share a little bit about what I’ve learned. I’ll have a video at the bottom showing whatever specific sounds I mention here.
I fancy myself a budding foley artist. And since telling people that usually raises more questions than it answers, “foley artist” is a term originally applied to movies for somebody who records sound effects that weren’t picked up by the camera. However, since then the term has been extended to other media as well, so I use it to distinguish the fact that I create my own sound effects rather than pull them out of a library. Most projects do a mix of both, but I’ve been challenging myself to get as many sounds as possible with foley to expand my range.
Foley for a video game is a completely different set of challenges from foley for a movie (or at least in this case; I imagine it would be closer if Frogatto had more cutscenes). The majority of what movie foley artists do is footsteps. They put on the pair of shoes they own that most closely matches what the character is wearing (I’ve had a hell of a time looking for a pair of heels that fits my size-thirteen feet) and watch the footage, walking in sync and timing their movements to match the actors’. Not only does their rhythm need to be perfect, but since they have a microphone pointing at their feet they have to walk in place and still make it sound natural.
I don’t have to worry about any of that. It’s impossible for every footstep in a video game to make a unique sound, because any given character will take an infinite number of steps. So I just supplied about ten footstep sounds for each of Frogatto’s different podiatric movements (walking, running, jumping, and skidding) on each of the surfaces we have in the game. And I didn’t have to worry about my timing, because the game just picks one sound from my collection at random every time Frogatto hits the frame of animation where his foot hits the ground. So all I had to do was pick my favorites, crop them, and upload them. Footsteps are the bulk of the job for a movie, but for Frogatto they only took a few hours. It took me longer than that to clean up all the scattered bits of confetti that stuck to my feet and tracked all around my apartment after I used them for shrubbery; I was still finding pieces when I moved out.
But even though this project has allowed me to bypass what appears to be the toughest part of foley work, I’ve faced plenty of hurdles that aren’t an issue for movies. Most of them deal with the unpredictable flow of action; while a sound well-chosen, well-edited and well-timed in a movie will be great every time you watch it, events in a video game unfold a little differently for each player. I have to make sure my sounds meet the needs of the game under every circumstance.
Most importantly, I have to be mindful of which sounds will be heard repeatedly and make sure they won’t be annoying or overbearing. Something that sounds cool once isn’t necessarily going to hold up over time. I contributed a few sounds to Cube Trains. One of our programmers’ other side projects, as well as a beautiful demonstration of the flexibility of the Frogatto engine, Cube Trains is a puzzle game where you build a track to get trains from one side of a map to another. The creator initially wanted me to do some big metal clang sounds for the laying of the track, but we agreed that since the player is laying track with every click of the mouse, those would grow tiresome rather quickly. So we scrapped the clang and went with more of a clink; to get a nice snappy metal resonance without a lot of reverberation, I wound up hitting my microphone stand with a slap bracelet. The nineties will never die.
Sometimes, I find myself needing to deliver sounds in such small pieces that I have no idea what they’ll sound like until they’re in the game. In our next release, you’ll notice that we’ve diversified the death animations of our enemies. As a result, many animal-type enemies now die by bursting into a flurry of bones. Jetrel’s inspiration was a similar effect from Secret of Mana for the SNES, but whereas Secret of Mana’s enemies skeletonized with a single self-contained animation, ours do so by turning into a bunch of individual and separate bones that bounce several times along the ground. Secret of Mana had one “bones-rattling” sound synched up to the animation, but I couldn’t do that because our animation’s timing is always different depending on the terrain. So I did about ten takes of flicking my fingernail against the bottom of one of those plastic ramekins a restaurant gives you when you take sauce to go, and had the game play one at random every time a bone bounced. Alone, they don’t sound like much, but in practice they make a nice little macabre symphony.
And while the coding makes it easier to sync audio with specific actions, it can also throw me some curveballs. I feel quite blessed that even with zero programming background Frogatto Formula Language has been extremely accessible. If I want to, say, add a sound for an enemy shooting something, I’ll just go into the enemy’s data and search for the command that creates the projectile and I can add a command to make the sound happen simultaneously, guaranteeing it will by synched each and every time. However, as I assume is the case with any programming language, FFL will follow the letter of what I say and ignore the spirit. For example, I made a sound play every time a particular enemy was injured. Most of the time it sounded fine, but Frogatto also gets an acid attack that rapidly scores damage over the course of a few seconds. If this enemy was caught in a patch of acid, the game would play my sound every time damage was sustained, which was all of the times. So we had to put in an extra condition dictating that every time the enemy was damaged, it would check whether the sound had played within the last few seconds and decide accordingly whether to play the sound.
But implementation aside, this has mostly been a surprisingly simple process for me. There isn’t much high concept here; I just picture what any given action would sound like and try to make that sound with whatever I’ve got on hand. Frogatto grabs onto a wall? Slap my hands against things. Frogatto spits acid? Pour some champagne and record it bubbling in the glass (as for the sound of expelling acid from one’s stomach… let’s just say I’m glad I can belch on command).
On the other hand, sometimes I need to make a sound for something that doesn’t exist in the real world and I’m shooting more for a “feel” than a re-creation. Our forest area has giant spiders that crawl around on the ceiling and try to pounce you when you walk under them. My microphone isn’t going to be picking up any sounds made by a spider anytime soon, so I was just looking for something sudden and startling. I made the sound by scratching my fingers across a duffel bag, and topped it off with a little “spider chatter” by rapidly repeating the sound of two eggs clicking together. We also have some synthetic plasticky golem-type enemies who pop when they die. Since I didn’t have any plastic golems handy to smash, I made this sound by throwing handfuls of flour against an empty bathtub.
Other times, the real sound just isn’t as pleasing as it could be. Our last area has spike traps that shoot out from the ground and retract. At first, I tried to make a mechanical release sound, but it just didn’t do them justice. So I made a few of those lovely *SHING!* sounds by scraping a hinge across the edge of a glass table. I can’t imagine real spikes ever making a noise like that, but who’s going to complain? If you have first-hand experience with spike traps, either your real life is way too cool for you to have any interest in video games or you’re some creepy baron in a dank castle and you probably don’t have internet access.
Here are some demonstrations of the specific sounds I mentioned:
So that about sums it up for my adventures in videogame foley. If anyone needs me, I’ll be over here spanking an empty bottle of apple juice with a sock filled with BB’s.